Too often in software engineering people are too quick to focus on the latest technology and reticent to develop their knowledge of the fundamentals. I suppose the reason for this is to build marketable skills. Recruiters and employers tend to focus on the technology their hiring managers (often other engineers) ask them for, which is usually the latest shiny thing and so the cycle continues.
Let’s start with describing what I mean by the fundamentals with some examples. The first set are typically the things you’d learn in a good Computer Science undergraduate programme. Examples are:
Data structures
Algorithms
Operating system design
The next set are generally good things to know for any software engineer but aren’t always covered in mandatory modules in CS degrees. Things like:
Design patterns
Networking
Low level computing
Cryptographic primitives
Bit twiddling
I could go on but you get the idea, you won’t regret learning these things, whatever you go on to do in software engineering you’ll find them useful, possibly essential. They will help you learn the latest shiny technology more quickly because you’ll know the building blocks of such things.
There’s more too, if you skip learning one to two cycles of shiny things you won’t notice it in a few months or years. Does anyone regret not learning grunt, then gulp, then webpack, not really, you just need one that works and nothing too bad happens if you skip one. Have little to no knowledge of networking or algorithms you’re severly going to limit what you are capable of.
So, should you avoid learning shiny new technology altogether? Absolutely not! Whilst learning those technologies you’ll pick up reusable skills for other tech, but guess what, those reusable things are the fundamentals. Thus if you want to accelerate your speed or learning, reduce those difficult learning curves, make sure you’re spending enough time looking at the basic underpinnings of computer science, they’re so important.
This topics comes up a lot: “how do I do authorization for my service architecture?” or if they are hip with the kids “how do I do authorization for my microservices”. The answer to both is the same…
Firstly some definitions:
Authentication
the process of confirming, to a level of certainty, a user is who they say they are. Often this is done with a username and password pair, but could be done with a certificate, PIN, token, fingerprint or anything else.
Authorization
the process of making sure that people can only do the things they should be allowed to and see the data they should be allowed to.
The Authorization-as-a-Service Anti-Pattern
Now at first guess it might make sense to have a service that does authorization. Why not, you can put all that complexity in one place and not worry about it anymore, safe in the knowledge that all that difficult authorization logic is encapsulated.
Trouble is when you add a new feature in an other service you need to make a change to your authorization service, to enforce the correct access to that service. It turns out everytime you make a change to any other service 9 times out of 10 you are then making a modification to the authorization service. This quickly gets tedious - it smells wrong.
Say you decided to live with the inconvience of the above double modification problem, who do you get to maintain and run the authorization service. You could have one team do it. However fairly rapidly they are going to be inundated with change requests, because every change to any other services needs a change to their service (most of the time at least).
The other option is to allow the teams who require the change to make the changes to the authorization service themselves. Trouble is then you have many teams churning a service’s code base that they don’t own then they don’t feel, indeed literally they don’t have, ownership and that’s a recipe to declining quality.
On top of all this, the releases of the authorization service needs to be sychnorized with all the other services that have been modified recently. Pretty soon you are in a stop-the-world type release process where every service in your estate needs releasing at the same time. The logistics are a nightmare.
The Solution
The simplest solution to the problem is to have authentication as a service; that is proving I am who I say I am.
Once you have the ability for a service to determin within a level of certainty that a user is who they say they are, then you can do authorization in each service. What better place to have the complex logic of who can do what than in the code that does the what.
For example consider a service that is responsible for providing access to a financial trading platform. It allows brokers to buy and sell a stock. Now the service might be aware that certain brokers can only buy €100k of the stock each day, it keeps track of this, because that’s what it does, rather than reaching out to an external service to ask, it has the information right there, it knows who you are, what you’ve bought and the rules for how much you can buy - it’s cohesive. Now say you want to change it so that brokers can only buy stock Monday through Friday, again all the information is there. There is no need to go anywhere else.
Perhaps you might write a library, a shared object, dll, jar or npm for it that others can reuse. JaaS and implementations thereof are a good example of something approximating a good design here, but don’t create a service, you’ll regret it.
Developers, software engineers, smart people, people have needs, these needs differ and certainly differ in weighting from person to person but I think the below lists the key desires of most. I, of course, can’t speak for everyone, I would however, like to be as complete and thorough as I can—I’m a techy, it goes with the territory—so please contact me if I’ve missed anything. Whilst this post is focused on software engineers it could equally apply to any profession that needs brains and experience.
I believe strongly that software engineering is a creative process. Not only is it a creative process like painting, making a photograph, giving a speech or product design it also requires large amounts of technical expertise. That’s it’s, an inate gift and hard earned knowledge and then, if that weren’t enough, determination to be successful and with the right environment: successful with others. These people are therefore incredibly hard to find, these are the people that will change the world.
People like these, people like you, can change the world, people like you have changed it, it’s sappy, I’m sappy, I won’t appologise. Below are some notes for your prospective employeers, custodians of your working life whilst you let them, I hope I can make a reasonable job of it.
Respect them
It pains me that I have to even say this: engineers deserve respect, they do a extremely mentally challenging job and the good ones, they’re smart, damn smart. When you treat them like children by taking away decision making power, coating their days in pointless process due to lack of trust or, worse of all, not listening to them then you do everyone a disservice. You won’t get even a tiny fraction of the benefit you could get out of them.
“Imagine what you’ll enable people to achieve if you believe in them”. \
— Dan North
So do it, believe in your people, let them know by showing them respect.
Listen to them
Listen to software engineers, they have opinions not just on software engineering but on everything from product developement, through personnel and on through P&L, they may not be right all the time but if they are as smart as you want them to be then they’re going to be right a whole, at a minimum they’ll give you new angles. Listening is the foundation of respect.
Other developers like them
Software engineering is a team exercise, of course from time to time we need alone time to think, but most of the time bouncing ideas of like minded people is going to be the best course of action. Be it pair programming, whiteboarding new ideas or discussing the latest technology over lunch, great software engineers like to spend time with other great software engineers, it makes them happy—fundamentally happy.
Remember software engineers, especially open source developer are ahead of most in terms of interacting online and therefore being part of a team doesn’t need to mean physical proximity, it could be via hangouts, hipchat or even good old IRC.
Fundamentally they want to work with other smart people with a common purpose, best make that common purpose yours.
Other smart people
Great developers want to work with smart people in other disaplines too. This could be product development, sales, marketing, procurement or personnel. It helps everyone grow, so unless you are running a production line (and why wouldn’t you automate that?), then make sure you only hire the best people throughout your organisation. Perhaps I’m stating something obvious: hire smart people—what I mean is hiring is the most important thing you do.
Access to tech conferences
Even when you get the best engineers working together in a team, with the best professionals in other disaplines, the knowledge and thinking can get a little stale. Engineers, we like to get out and meet other likeminded souls who haven’t been our team mates for years. Some of us even like to speak at conferences (cough), firstly because it feels good to share information, be part of something bigger and secondly it’s because it provokes a conversation. Let your gals and guys out once in a while, pay the airfare, put them up somewhere nice and let them meet other smart people.
Companies that talk about their (cool) technology.
This goes hand in hand with the conference attending, if you speak about the great things you are doing then people are going to want to come and work on them. Smart people want difficult challenges and they want to solve them in smart ways and then they want to brag about it. Smart people who want to do this and can’t are on the constant look out for those that will let them.
One word of caution, if you technology isn’t great you’ll do more damage than good try to palm it off as good. Either be honest and speak to the challenges or don’t bother.
Freedom to express their views
The best engineers tend to be opinionated (the reverse doesn’t necessarily apply) and so by definition they like to put forth their opinions. If you restrict them from doing so you’ll firstly make them sad and secondly deny them the chance of being challenged and finding out there was more to learn (there always is). Also be prepared for this taking multiple forms, for some this could be a posting on a message board, other it might be an empassioned monologue during a meeting but best of all it might be a commit to github.
Open source
Behold! Code, what makes software (goto?)
If your software is closed then it makes it very hard for your software developers to engage with the outside world of software engineering in a meaningful way. It also takes away their ability to show off what they’ve been doing. Smart people like to show other smart people how smart they are from time to time. They do it a little for their ego but mostly to start a conversation with other smart people and learn.
By putting your software out there you’ll show the world that your company is made of smart people too and you’ll capture their attention, perhaps they’ll help you write your software, perhaps they’ll become a colleague (perhaps they’ll be your boss [ssshhh]).
Hardware & software they need/want
I’ve lots count of the times I’ve heard engineers lamenting being fobbed of when asking for better equipment. The logic goes something like, we have a standard build, it will only work on this configuration and it’s good enough for the guys in legal (no offense) so suck it up (of course most budget holders will put it more nicely than that but the engineers will hear ‘we don’t value you’).
Just stop it, let your software engineers pick any laptop, desktop, mobile phone or flux capacitor they want and as long as it doesn’t cost the price of a new family car every year, go with it. It will make them more productive, happier and ultimately it’ll save you money in time spent discussing it—don’t believe me, want a business case, tough, you won’t get the best techs to work for you if you don’t.
Safe environment for innovation
Everyone should be allowed to innovate, it shouldn’t be scheduled and it shouldn’t be the sole perview of a few chosen individuals, if you want to spend time looking into Huffman Coding and using it to increase data read times from disk then that’s what you should do—who else but the smart person thinking about that problem is going to have a better opinion of whether it’s a waste of time or not? Bear in mind it might not be her ‘job’ to be worrying about data density read speeds, go with it, what’s the worst that could happen?
A career path
It’s no longer good enough to force your best engineers to be people managers once they hit a certain pay grade, a few might want to, let them, but most won’t: so stop it. Give them something else to aim for that gives similar benefits: reward package, pension, car, bonus, blah. What else is there to aim for you might wonder, if it not a big team and a huge budget? It’s probably access to hard problems, large amounts of hardware, time and people but, you know, ask them, they’ll tell you.
Minimal politics
Normal people dislike office politics, engineers dislike them even more, make sure you have an office that is focussed on your purpose not playing silly beggars; enough said.
Minimal process
Have the absolute bare minimum of process that makes you feel comfortable, see how it feels and then remove some more, after about 10 iterations of this your probably where you need to be. The more process you have the harder it is to change and technology is all about change, therefore the more process you have the less likely it is that you’ll have great technology.
Meaningful appraisals
Appraisals are mostly theatre, make what happens useful and remove the rest. Make sure that someone that understands what the individual does leads the appraisal and don’t leave it more than a week to give positive or negative feedback. As a great boss of mine once said, appraisals shouldn’t be a 6 monthly surprise. There are entire libraries of books on this subject but that’s about the size of it. Everyone wants to know, objectively, how they’re performing, even or perhaps especially the best performers suffer from imposter syndrome, so let them know they’re doing a great job and don’t make them fill in a 10 page form every 6 months.
A company with a purpose
The worst possible thing is to have no meaning. A recent article talked of gifted people being plagued by feelings of meaningless, more than those less able. If your organisation has no common purpose then talented people are going to feel it more keenly. Have one goal, communicate it, then communicate it again, when it doesn’t happen, ask why, make changes, involve your engineers and keep communicating it. Did I mention you need to communicate your common purpose? What is it? Write it down, write it on the wall in spray paint, write it on every wall. If that purpose doesn’t interest them, shake hands and move on, if it does you can guarantee they’ll be fired up to know that everyone cares and that you care.
One of the oldest project management concepts I can remember being told about is the project management triangle. Whilst the project management triangle is largely misleading and quite frankly dangerous if taken literally it does at least tell you one thing: there are trade-offs in any given endeavour. For the classic project management triangle the trade-offs are three things with quality overlaid in a clumsy way. Those things are: cost, scope and time.
The theory is:
If you have enough time and money you can deliver your scope
If you have enough time but not enough money then you’ll have to deliver less scope
If you don’t have enough time but enough money then you’ll also have to deliver less scope
If you don’t have enough time and money then you are doubly in trouble and likely won’t deliver much of anything
Of course this is a very naïve way of looking at things and won’t get you very far. It doesn’t take into account things like morale, motivation, team politics, shared purpose, force majeure, health, ethics, sickness, personal life, indecision, competitor disruption and all those things that make humans and business such wonderfully complex and interesting things.
The triangle, as I’ve mentioned, has quality as its background, meaning I suppose, you can sacrifice quality to claw back time, costs and/or scope. Think about this though, can you really? Perhaps you can in the short term, how about the long term? If my team and I produce shoddy code that’s hard to read, has scattered concerns and global knots and all those bad things, then how am I going to keep delivering to functionality, at pace and within reasonable costs? This seems obvious, however it is missed or ignored remarkably often in small and large organisations alike.
The point is that if you sacrifice quality for short-term delivery of scope or to keep costs down then it will cost you more or you’ll get less in the future. Moreover it will cost more, take longer and deliver less for every subsequent project on that system. Until you’ve improved the quality back to an acceptable level you’ll be paying for that quick or cheap delivery in opportunity cost. Worst of all at a certain quality point the quality deteriorates faster and faster - interest is accuring on that technical debt.
Technical Debt
Ward Cunningham coined the term technical debt to describe this and like real financial debt it isn’t always desirable to avoid it. Just like in business taking on some debt can be a good thing, it can allow you to grow your business faster than otherwise and pay it back before the interest mounts. The same is true of technical debt. However, just like financial debt, if you keep on taking out loans and not paying back any of your debt the interest mounts and eventually the insolvency officers move in and shuts you down.
In software terms the insolvency will manifest in a number of different ways, technical bankruptcy looks like:
Every time you introduce a new feature another feature breaks (sometime referred to as the whac-a-mole problem)
Many of your best people leaving because they cannot take pride in what they are building (usually you end up with a churn of short-term contractors before eventually that costs too much to justify)
A competitor out pacing you and taking your customers
What we have to do is look at the reasons for poor decision making and ensure we can avoid them. Why do organisations, decision makers ignore software quality and therefore long term growth to pursue short term goals?
Financial Cycles
Most companies run their finances monthly and then annually, there is nothing else that matters to some people than the end of period figures. If you’ve ever spoken to an accountant at the end of the month they are usually a jibbering wreck from burning the midnight oil and if you speak to them during end of year you can forget any chances of getting some sense out of them. Not that the accountants are to blame they are just the messengers.
This is because the books have to be closed, the results have to be calculated and everyone wants them to look as good as possible to investors, bosses, themselves or whoever. What this creates is a sprint for the line at the end of each period. What happens when you sprint for the line? You give it everything you’ve got, abandon all strategy and then collapse in a heap once the line is passed.
In software quality terms this is a disaster. It means that everyone burns the midnight oil, shortcuts are taken to get features in, testing slips and shortcuts are taken. When all is said and done a few targets might have been reached but actually the code is now a steaming heap of rubbish.
Hidden Cost
In order to really understand software quality you have to really understand software, this means understanding many complex things like: systems design, software design, at least a few programming languages, data design and so one, who understand these things? Not many people, that’s who, and these people are busy creating new software and not explaining the implication of poor quality software in a language business types will understand. Typical those people, as bright as they are, aren’t the best a translating software quality issues in to monetary figures.
It’s by the nature of the complexity of the problem that few people understand its implication and often not the people (trying) to count the costs.
Opportunity Cost
This is a huge hidden cost and as such is called out separately. Opportunity cost is the difference between the value of the selected approach and the best alternative. In simple terms if I select an approach that makes me £100 over one that would have made me £250 then I have an opportunity cost of £150.
It’s an interesting concept and it applies to software in the following way. Let’s for example say I want to add a cool new feature to a mobile app. It costs £1000 to write the code to do it one way (code change A) and £3000 to write the code a better way (code change B). The first reaction is to pick A. However code change A will increase support costs by £250 a month. Moreover it will make the cost of doing the next change £1000 more expensive.
Now the opportunity cost is £250 after the 5th month and growing every month. Moreover it might mean that the next change doesn’t get made because it’s too expensive or worst still it is done in a suboptimal way meaning that it too increases opportunity cost compounding the problem.
Transient Team
A stable team is key to keeping a good quality software product. If you know you are going to be looking after the software in 3 years’ or 5 years’ time you are going to have a lot more invested in making sure it works and that it is a pleasure to support than someone who’s going to be off at another company or client in 3 months’ time.
Don’t get me wrong, I’ve worked with some amazing and dedicated people who’ve came and gone from teams quickly for whatever reason, however, on the whole, the tension isn’t there to think long term.
Unengaged Team
Things get to a point where design decisions have been overridden so many times to meet short term goals that the team stop fighting it. When this happens it’s a sad thing, you have an unengaged team who can’t take pride in their work and aren’t delivering the value they are capable of.
Reward Schemes
Similar to financial cycles more often than not companies will award bonuses annually for meeting certain goals. Getting a certain number of features added or perhaps getting X million sign ups or shifting Y million licenses. This triggers the target fixation mentality, where anything and everything is done to get these things achieved no matter the debt and damage incurred to the quality of the software.
Additionally next year’s bonuses will be negotiated from the point of knowledge of the software at the end of this year. Highly debt laden system will have the bonus hunter negotiating for lower barrier goals. If they don’t get them they move on and someone else moves in and does the same anyway.
Some Solutions
Listen to the Experts
There are no easy solutions in this, however things that help are a voice for the people who understand the complexity of good software. Listen to you developers, listen to the designers and architects. You’ve hired them for their expertise so use it.
Help Them Explain
Accept that the technologist might not be able to put a financial figure on the costs, help them with that, come up with mechanism that works for both the technologists and the accountants, make balanced decisions based on the circumstances. Remember the best software solution might not always be the best decision for the company but it quite often is.
Manage Your Tech Debt Like Any Other
Have technical debt reduction as a metric that is rewarded equally or more than adding features.
Start to show technical debt on your P&L report, take it seriously because it is a very real thing that has brought down more companies than we’ll ever know.
Set Long Term Goals
Have bonuses rewarded over 3 years too, supplement annual bonuses with some longer term goals around software quality.
Stabilise Teams
Value a stable team over transient teams, do everything you can to keep the loyal people loyal and support them in their quest for long term software quality.
Summary
Software quality is incredibly important, it’s the long terms viability of any technology focused company. Without it you are entering a downward spiral to technical insolvency. Take it seriously, sure, don’t be frightened to add a little technical debt now and then, but do it consciously, record it and pay it back in a prudent manner.
Once you’ve been in the industry for a decade or so you start to get a sixth sense of when things aren’t right. However even when your sixth sense isn’t working here are some signals that should raise alarm bells.
1. It Dependencies
Every time you ask someone how something works or where some data is the explanation starts with ‘it depends’.
For example say I enquire how a user’s password is verified, I’d get an answer something like this:
“It depends, if the user registered before 2001 then you need to call the genesis logon system, after 2001 however we switched to active directory, unless the user was a customer of that company we bought in 2005, in which case you’ll need to call the ‘migration’ LDAP they put in place at the time which uses Netscape LDAP so you’ll need JNDI library we patched to work around some bugs. Also if the user is an administrator we keep the credentials in the staff database so you’ll need to do an ODBC look up for that.”
You get the idea, technical debt has built up, poor decisions haven’t been rectified and now there is there a laundry list of ‘it depends’ for every question.
2. Jane Doe
Here’s where we have a systems or component that only one person understands, the cynical might refer to this a mortgage driven development however it often happens because of apathy too. Unfortunately, the system might not be considered sexy to work on and therefore hasn’t been touched other than to keep it ticking over. The trouble is that every time there is a problem only Jane can fix it and she’s not much into do that work either. She’ll do the minimum to keep it ticking over.
The trouble with this is that the system is providing value to the organisation otherwise it could be turned off. It’s very likely if it’s providing value that at some point in the future it will need enhancing and nobody is going to be able to do and that — and then Jane quits.
3. Town Hero
This is the support equivalent of ‘Ask Doe’, it isn’t a case of if this system will fail but when and how dramatically… and it’s always dramatic. When it does go wrong there is only one plucky guy in support who can fix it: our local hero. Undoubtedly he’s not around when things go wrong but everyone knows he’s the only guy that can fix it.
When the inevitable catastrophic failure occurs calls are made to his landline, his mobile and DMs to his twitter account. He’s unreachable, what should we do? We’re doomed. When all seems lost a call is received. He’s been located, but he’s on a beach in Rio. There’s no way for him to connect to take a look. However he’s had an idea he’s VPNing into a server in Hamburg to create a SSH tunnel through the San Francisco DC and from there to the corporate firewall… he’s in! A few minutes later he’s diagnosed the potential problem. People are called to mission control, orders are given, procedures are ignored, changes are made. The hero calls into the bridge and explains the problem, it’s going to be tough and take some time but he can do it — nobody else has a clue what he’s talking about. In the small hours the system is restored, everyone pats each other on the back for pulling together and working as a team — also, more importantly, thank goodness for the hero, what would we do without him?
All is well in the world thanks to that guy, our hero — until next month, when the exact same thing happens again.
The trouble is these systems never get fixed, either because the team that that supports them aren’t qualified to do so, aren’t allowed to do so or because they are too busy, maybe too busy being heroes.
4. Carcinogenic Prototype
This system starts with a great idea, an idea that has a lot of potential. In order to qualify that potential a demo/pilot/prototype is created and as it turns out the potential is realised. The business become very keen to get this prototype into full production — they might just make those targets they thought they were going to miss if this works out. The engineers who built the prototype are pleased because their work is demonstrating value but reticent because it was just a prototype.
The engineers mention this to the group. The system wasn’t designed to go live, it doesn’t scale easily, it doesn’t have good exception handling, it doesn’t do any logging, it can’t be monitored, the list goes on. The engineers are overruled but promised to be given time to fix it up later.
Later never comes because once the system is live feature enhancements come pouring in, the system grows rapidly and sometimes starts to affect other systems too. Unfortunately due to the quality of the system it’s very hard to add features in a clean way and so the technical debt grows, it compounds.
Solution
As with most things in software engineering the technical problems are symptoms of the organisational causes. For each of the symptoms listed above there are numerous organisational reasons for them occurring, I’m going to start to blog each of these organisational issues over time. However at the heart of the problem is a lack of desire to change the status quo, to enforce a level of quality in the engineering and take ownership. Take ownership of your minimum viable quality and stick to it.
The microservice term has been around for a while but for as long as it has been around there has been much arm waving around what it was. It continued as one of those nebulous concepts that meant anything and everything to everyone and no one. In this way it caused a little confusion but served as a token to reference something — but what? The closest you could get was was that the services were smaller than monolithic applications, by some measure that was vague. Of course, as is often the case some people were tacking fairly arbitrary stuff onto the term too. That’s where we were, microservices were smaller than just about the biggest thing anyone can ever create in software: monolithic applications. Monolithic applications are like the Graham Numbers of software architecture.
“Graham has recently established … a bound so vast that it holds the record for the largest number ever used in a serious mathematical proof.” — Martin Gardner (c.1977)
This wasn’t particularly useful but pretty much par for the course in the IT industry, buzzwords come and go and often don’t have concrete meaning attached to them, or have multiple conflicting meanings attached to them. However this is where things took an interesting turn, Martin Fowler, a well known name in the industry made an attempt to document what the terms could mean. Fowler takes a very thorough approach to documenting things and has a rather large following of people, so when he does document something the term:
tends to stick
have concrete meaning
The trouble was that a number of people to a great or lesser extent, including myself, believed the definition of microservices that Fowler came up with is remarkably similar to SOA as known and documented, with some other practises thrown in. Those other practises were debatably a little orthogonal to the topic at hand, that is, they were good practise but beside the point.
It’s well documented what SOA is and now it is well documented what microservices are. Compare them side by side and most reasonable people, I think, will come to roughly the same conclusion. So how did this happen?
Marketing and communication
SOA is unfortunately a hard concept to grasp initially, it takes a little time, then most people, if they persever have an epiphany and wonder what it was that they didn’t understand in the first place.
Trouble is I think that only those who really went to town on SOA the first time around had that epiphany, but why did some go to town on it and others not.
What happened with SOA is that the waters were muddied with a large amount of esoteric and/or complex language, take a look at the SOA Reference Model for example, it has some very good information in there but it is an intimidating read and I can imagine that not many have read it. I would absolutely forgive anyone for not reading it, it took me about 5 quite determined attempts…
If you contrast this document to Fowler’s blog post then you can see which is more easily digestable. Fowler is (literally) an expert in the written communication of technical concepts, perhaps the best .
Vendor spin
As anyone who’s been in the IT industry for any amount of time will know for any given buzzword there are roughly a billion vendors trying to capitalise on it. This may be as simple as saying it is SOA enabled or microservice compatible but it can take more subtle forms too.
One of these approaches is to create a related standard or pattern. It wasn’t long after SOA started getting discussed as a concept that WS-* appeared on the scene with a seamingly endless parade of complex specifications and reference implementations of said specification. Each specification was dutifully implemented by the big vendors so that they could become ‘service-enabled’.
Unfortunately these specifications were awful, some absurd, moreover these vendor implementations didn’t work very well with each other, indeed some of them needed standards to defined the standards. That is a web-service exposed by one vendor couldn’t be reliable called by a client from another vendor. This left a bad taste for the right thinking engineer and there was violent push to the opposite end of the interface spectrum: ReST, JSON and so forth but that’s another story and one we all learned from.
As I eluded to early it wasn’t just specifications that clouded the SOA picture. In order to sell software licenses it was key to have something big, expensive and most importantly critical to the client once implemented. There is no greater example of this than the ESB. However I’ve written about why you don’t need an ESB before, needless to say this also left a bad taste.
For the record, to my mind, neither ESB or WS-* are desireable in a modern SOA. Unfortunately, sometimes WS-* is the only way to communicate with legacy applications. The industry did learn from all this, I hope.
Time fades
Finally, time fades, engineers like new things, I know I do. I like to play with new technology, think about and discuss new ideas. I’m also forgetful, I forget some of the cool things I once knew. As the expression goes, everything old is new.
Summary
For the most part there isn’t really anything new in microservices over SOA. SOA has some baggage of ESB and WS-*, that is some people confuse that with SOA, unfortunately vendors did that. For the record some of us gave them a hard time for that at the time.
Do we need a new term? I don’t think so, I think it would be more useful to tie down what we mean by SOA, clearly remove the bad things and highlight new thinking. However by renaming I think we revise history, we lose the discussion, the ‘changelog’.
My humble suggestion would be that it is more useful to highlight the difference, what’s new and give those things names, think of these changes as microbuzzwords.
Service Oriented Architecture is about making IT look like your organisation — your business. In many companies IT systems are broken down in to lumps that aren’t the same lumps that the business understands. You may have systems with mysterious names like Pluto or Genie or worse still impenetrable 3-letter acronyms (Steve Jones speaks to this in his book Enterprise SOA Adoption Strategies — chapter 12). How do the business and 3rd parties make sense of these meaningless and cryptic monikers? Usually they don’t. They only serve to isolate IT.
With this in mind, IT and the rest of the business have a daunting task of breaking down the organisation, its data and functions into services. One plan of approach to this is to look for things that are highly cohesive, that is, things that naturally belong together because of their very nature.
However deciding what belongs together can be like the proverbial pulling of a thread from a sweater, you pick one thread to pull it out and the rest comes along with it. You end up with long chain dependencies; everything directly or transitively refers to everything else. It’s a similar problem that ORM toolkits have, but this isn’t just about data.
Every data entity, every small bit of function or process in your organisation is related to another somehow, either directly or transitively. It’s 6 degrees of separation applied to your software estate and there’s no getting away from that fact. The extremely hard question is where does one service stop and another begin, where do I draw the lines between services.
I used the term “cohesion” earlier, its counterpart, its nemesis is coupling. Coupling is where something has been put together or joined with something it doesn’t strongly belong with. To using a banking example you don’t expect your staff payroll system to need modification when you change the way deposits to customer accounts work.
In short good dependencies represent high cohesion and bad dependencies represent tight coupling. The opposites of these are low cohesions (which is bad, boo) and loose coupling (which is good, yay).
The question remains, though, why is cohesion good and coupling bad. The advantages of cohesion are as follows:
Your brain groups naturally cohesive concepts, things that are like each other follow naturally. Cognitively working on related concepts at the same time makes sense.
Changes to one service are less likely to require modifications or have side effects on other services.
Services need to interact with each other much less, because for the majority of cases the functionality or behaviour of the services belongs in the service. This means that invocations can and data access can occur within the process space of the service, not need for network calls and data marshalling.
It makes it easier to reason about where functionality or data might exist in your services. For example if I need to change how salaries are calculated, that’ll be in the payroll service, it becomes obvious.
The disadvantages of coupling, somewhat the corollary of the above, are:
The service is harder to understand because you have to hold more concepts than necessary in your head when reasoning about the service.
Unexpected consequences, you change one piece of functionality and an unrelated one breaks.
Can lead to fragmentation of cohesive functions and therefore higher communication overhead.
You have to make changes to more code than necessary when adding functionality.
Types of Cohesion and Coupling
There is much written on this and so I’ll try not to rehash it too much, unfortunately I haven’t found anything that unifies well cohesion and coupling. What I’m going to do is referred to good types as cohesion and bad types a coupling.
Data cohesion (good)
Where data is often used together.
Example: a dating website would put a customer name and email address together because they are used together often. However they would not put suitable partners together will their credit card details
Functional cohesion (good)
Where functions are related and act upon the same data
Example: registering for a website and modifying your username might be two functions on the same service, whereas paying an employee’s salary wouldn’t belong there because functionally it makes no sense.
Categorisation Coupling (bad)
Things are put in the same service because they belong to a certain category of data or function.
Example: Used cars have a location and so do used car sales men so I’ll create a location service for them both.
Process Coupling (bad)
This is where services are created around long chain business processes. The problem with this is that business processes tend to go across many concepts within an organisation and so pull a lot of stuff with them — forcing you toward a monolith.
Example: A company has a process for the selection, purchase and installation of equipment. This process includes requirements for the equipment, knowing how to contact suppliers, how to receive invoices, how to make payments, engage with legal, specification of their property portfolio and so forth, before you know it you’ve got a monolith.
Arbitrary Coupling (bad)
This is where unrelated concepts exist in the same service. Who knows why, perhaps the systems designers had two projects and couldn’t be bothered to have two separate modules in their IDE.
Example: most enterprise off-the-self business software, although things are slowly getting better.
Data Type Coupling (bad)
This is where services use the same definition of a type and when one needs to modify that definition it breaks the other.
Example: A company has a single definition of its customer type, the properties of that type are defined (think global XSD for customer data). Each service that deals with customer has to be capable of understanding this customer type. One day marketing decide they want to add twitter username as a new field. This means that all services now need to be updated to include this field when talking to the marketing service as it’s now fully expecting it.
Temporal Coupling (bad)
When two concepts happen at the same time but otherwise they are unrelated. This is similar to process coupling and is often a symptom of that.
Example: Every month accounting complete their books and makes sure they balance, they also run payroll, the account service is created to do both these things.
I do a lot of programming in the large and spend far too much time, according to some, thinking about programming in the large concepts such as SOA and CEP but from time to time I like to keep it real and code something detailed and low(er) level. Recently I’ve been doing a little investigation around compression and so I ended up reading up on Huffman Coding. Huffman coding is a way of taking a fixed length encoding and turning it into a shorter variable length encoding.
Back to basics
That’s a little vague and academic so I’m going to assume little knowledge of how computers store data and work my way up and see if I can explain it properly.
Figure 1. On off switch
Computer storage is made of switches, lots and lots of on/off switches, a switch in storage terms is called a bit and is the smallest possible unit of storage. Switches can be on or off and computers represent that on or off as 1 or 0 respectively. That’s why the classic power switch on most devices is a zero with a one overlayed as in figure 1, 0 and 1 mean off and on to engineers. If I only have 0s and 1s then I’m going to have to find a way of representing numbers bigger than 1 using them.
Getting to second base
Classically we use a numbering system with ten digits zero through to nine, which mathematicians would call base 10 or decimal. However as computers only have two digits they use a counting system base 2 which is referred to as binary. To count in binary we simply increment the number on the right until it reaches its digit limit (1) and then increment the number closest to it on the left whilst reseting that number to zero, if the number on the left is also at its limit we move again to the left and reset it until we find one we can increment, this is exactly the algorithm we use for normal counting. Therefore we have
Interestingly and logically where in decimal the first digit represents units and the second tens and the third hundreds, in decimals they represent 1, 2, 4, 8 and double for each digit to the left. Thus 101 (binary) is
(1 × 1) + (2 × 0) + (4 × 1) = 5 (decimal)
Anyway enough about bases, I think we have that covered off. What we need to understand is you can represent numbers using sequences of zeros and one on computers.
Encoding
Computers encode many things to files such as text, images, video, CAD models and many more. Let’s choose the simplest thing possible, though, for our example: text. To have text file we must have some way of mapping numbers to/from letters, what computer scientists call character encodings. Whilst conceptually simply these things stike fear into programmers who are smart enough to understand what they are and what a mess we’ve created for ourselves. I’m going to dodge the bullet of fully explain why they are a pain and use the simplest one as an example. US-ASCII, which is the seemly tautological United States-American Standard Code for Information Interchange, as an example character encoding.
US-ASCII defines a mapping of numbers to characters. Each character is represented by an 8 binary digit number known as a byte, remember a binary digit is called a bit, so a byte is an 8-bit number. The reason numbers are stored as 8-bits is so that they can be read off storage easily. Remember there are only zeros and ones on computers. Therefore to know where a number starts and ends there has to be some way of splitting them back apart. A file contains for example:
0100111101001011
Which is two bytes of data namely 01001111 and 01001011 or in decimal 79 and 75 or in US-ASCII encoding “OK”.
ASCII defines which numbers represent which characters, for example ‘A’ is 41 (decimal) that is 01000001 (binary). As it just uses 8 bit numbers there are only 256 characters possible (i.e. 00000000 (0) through to 11111111 (255)). Full mappings of numbers to characters for ASCII are availble all over the web.
Let’s split
You might be thinking why bother with the leading 0s on each byte in the “OK” example above, well if I did that I would have
10011111001011
and how on earth do I know which digits belong to which number, it could be 10011111, 001011 or it could be 100111, 11010101 indeed there are 13 possibilities assuming I know there are two numbers represented, otherwise it could be 14 numbers or 1, basically I’m screwed if I don’t know the length of the numbers in bits. I can’t add anything to separate them because all I have is zeros and ones and I can’t use a zero or one to separate them because I won’t have anything left to count with; you can’t count in base 1. Therefore in order to put numbers in storage I need to predetermine a length for those numbers in bits and stick to it. The general building blocks of information in computer science is 8-bit bytes and that is why.
To summarize, we have numbers represented by 8-bit bytes and we have a mapping of those numbers to characters assuming we are using US-ASCII. However forcing all numbers to by 8 bits seems awfully wasteful. Let’s suppose I want to store the sequence of 20 characters:
ababababab
Well in this case I only need two numbers to do so so I could just store them using a basic character binary encoding of 0=a and 1=b. Therefore rather than using 8 x 20 = 160 bits of storage I could just use 20 bits. To spell it out I could use
This is huge storage saving in percentage terms. It’s important to point out that an encoding maps one set of symbols to another, in the case of ASCII it is 8-bit bytes to common western characters, for Huffman it is variable length binary sequences to 8-bit bytes. Therefore what’s actually happening here is:
a (ASCII) -> 10001101 (8-bit byte) -> 0 (Huffman)
Now what if I have 3 characters in my sequence:
ababababac
This presents a problem for the encoding technique above, because I have no obvious way to encode the ‘c’. If I use the next number in the binary sequence namely 10 for c. I have a problem that a sequence such as cba:
1010
has ambigious meaning, it could be abc, cc, bac or cba, not much use. However, and here’s the key insight, suppose I only use zero/one sequences that don’t appears as the beginning of any other sequence to represent 8-bit numbers. Therefore I pick 0=a and because I can’t use a number starting with 0 after picking 0=a I must use something like 10=b leaving 11=c. I can therefore unambigiously encode cba as:
11100
There is nothing else it can be but cba. I don’t need to know the bit length of each number to decode. To work the example the first digit, 1, this isn’t a character, nothing is encoded as 1 so I add the next bit to it and get 11, well that’s c there is no other number starting with 11 so I can unambigiously decode it. Similarly with 10 and 0.
The algorithm
The aim of Huffman Coding is to create a shorter encoding that the original fixed width encoding. Indeed it is a little more than that, it is to get the shortest possible encoding unambigious encoding. How do we find this out? Well first a few things about Huffman Coding. The genius of the algorithm is that it is simple and will always find the optimum (shortest possible) encoding and this encoding will always be less than or equal to the length of the equivalent 8-bit encoding.
Tree hugging
Firstly I describe the algorithm then I’ll do any example. As we know US-ASCII is simply a sequence of 8-bit bytes as is every other file on your computer (on the vast majority of modern computers). Therefore we have a sequence of bytes.
Huffman encodings use trees, Huffman trees, to describe their encoding. A Huffman tree is a binary tree, in that each branch gives way to 2 or fewer branches.
So the algorithm:
Count the number of occurences of each byte in the sequence and put them in a list
Sort that list in ascending order of freqency
Pick the two lowest frequency bytes off the top of the table and add them to the tree as two branches on the trunk
Add the frequencies of those two nodes together and add that part of the tree back to the list and sort the list again in ascending order of frequencies
If there is more than one item left in the list then go to step 3, otherwise you are done, the last item in the list is the completed tree
Example
In this example we are going to encode the string: “Mississippi hippies”.
Here’s the frequency table:
[_,1]
[M,1]
[e,1]
[h,1]
[p,4]
[s,5]
[i,6]
Note I’ve substituded [space] for the underscore character “_”.
So we take the two smallest values off the top and create our first part of the tree, hopefully the notation is self explanitory the tilda (~) means that it is just a node and the letter before is simply and identifier, the leafs have the character they represent and the frequencies:
z[~,2]
/ \
/ \
[_,1] [M,1]
We add this back to the list
[e,1]
[h,1]
z[~,2]
[p,4]
[s,5]
[i,6]
Then the next two lowest frequency items
y[~,2]
/ \
/ \
[e,1] [h,1]
Adding it back in gives
y[~,2]
z[~,2]
[p,4]
[s,5]
[i,6]
Then the next two (which are both sub-trees) gives
There we have it, our final Huffman tree. How do we use it? Well in order to find the encoding for each letter we travel down the tree until we get to it. When we go left we add a 0 when we go right we add 1. For example to encode ’e’ which is a rare character in our input string we get the following:
0000
Or for ‘i’ which is very common in the input sequence we get
11
a much sorter encoding. From this tree we can build an encoding table as follows:
_ 0010
M 0011
e 0000
h 0001
p 01
s 10
i 11
Thus we can encode the orginal string “Mississippi hippies” into:
Which is 46 bits rather than the (19 x 8) 152 of the orginal. We’ve compressed 19 bytes into 5 bytes (last byte is zero padded).
A couple of notes:
For input with almost every byte possibility and roughly equal frequency of those bytes compression will be very limited — large movie files for instance.
For some encodings certain bytes will encode to longer than 8-bit codes, but the shorter encodings will at least offset those
Huffman tree can be stored very effiently using a fix length format, pick the left then the right, move down to the left and repeat until the tree is traverse. When you hit nodes in the tree that are leafs output 1 followed by the value (not the frequency), when they are nodes that are simple parents of others output 0 followed by nothing.
This was a pretty fiddly blog post, please let me know if I’ve made mistakes in the comments or email.
When people start to service orient their organisation they often focus on exposing APIs and those APIs invariably solely or mostly focus on method calls, what I and others often refer to as RPC. This is great and brings huge benefit but it does miss a huge opportunity and that is being able to observe and react to what’s happening in your organisation.
In order to be able to observe and therefore react to whats happening in the services that make up your organisation you need to add events to your services. What do I mean by events? To start with let’s leave technology aside and think of the business problem you might be trying to solve. As an example let’s take a retail bank that offers current (checking) accounts. To model this account appropriately there are things that should be modelled as RPC and things that should be modelled as events. If a customer uses an ATM to check their balance this should be RPC, the ATM will call the account service to get the current balance to display it to the customer. There is little point in doing this as an business event because you need the output of the customer asking for their balance to continue.
Now suppose the customer wants to make a withdrawal, this would cause an RPC type invocation (i.e debit £100) and an event (i.e. user withdrawal occured on account id 5123). The RPC call allows us to perform a blocking operation to check there is sufficient funds, make the deduction and inform the ATM that it can dispense, the event will be published for interested parties to be informed that something they might be interested in has happened. Who might be interested in this event? Well it could be an analytics package that wants to keep track of which ATMs are popular or maybe a complex anti-fraud system figuring out suspicious patterns of withdrawals.
The great thing about events is that the systems raising them doesn’t need to understand how they are used they can simply raise them and go about their business. In the example above suppose you were asked to add a feature where customers could have details of their withdrawals emailed to them. Rather than go in and change the mission critical code around financial transactions you could set up a service that listens to these events and when it sees one email the customer. The team that looks after the account service need not even know.
Events start to get really interesting when you combine them, what some folks call this Complex Event Processing (CEP) but I prefer to consider a fairly logical part of of Event Driven SOA.The ‘complex’ in CEP refers to the fact that multiple events are combined to infer or derive something more interesting has happened. This is all a bit theoretical so let’s revisit the anti-fraud example from earlier. A security analyst has identified that when a customer makes withdrawals from ATMs in two different counties within the space of a day then this is suspicious but not impossible, it might raise an event such as “Customer Crossed Border” event. If the customer goes on to make high value transactions in the first country then the matter needs investigating as another “Customer Crossed Border” event occured on the same day as the first. The fact that this has happened would raise an “Suspicious Occurance” event which the account system listens to and locks the account. When the account is locked an “Account Locked” event is raised with a reason code; the customer support centre service listens on this event. When one is received a task is added to one of the call centre operatives list of work (i.e. call customer and verify transactions) and so on.
Please don’t get me wrong you shouldn’t expose all data and behaviour solely via events, this would be ridiculous but I’ve seen horror stories of people doing so, indeed I’ve worked to put them right. What I’m advocating is using a balance of RPC and events to best represent your organisation in an SOA fashion.
I’ll talk more in future blog posts about patterns for adding and utilising events in your SOA.
ESBs irk me, not the technology in and of itself, that can be useful, it’s the way they used. Mostly because every architect and his mentor seems to think you can’t have an architecture without one. I swear sometimes they must have the ESB icon pre-painted on their whiteboards because, splat, there it is, a hulking great rectangle in the middle of every systems diagram. They aren’t always called ESB, sometimes they sneak through as ‘Orchestration’ or ‘Integration Hub’ or a vendor product name.
I first came across the term ESB about 10 years ago, a colleague mentioned them to me and we discussed the concept over lunch, by the end of the lunch break we’d come to the conclusion they weren’t necessary or indeed desirable in an SOA. I’ll put forward some of the classic reasons architects give for using ESB and explain a better way to achieve each desired outcome or in some cases why that outcome isn’t desirable.
Before I go on I should explain the difference between the central ESB (bad) and using ESB technology in a more appropriate manner.
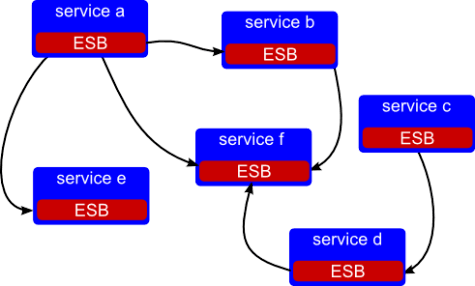
Figure 1. An ESB used in an inappropriate way
Figure 1. shows an ESB through which all services communicate, they are essentially unaware of each other and may be in the dark over what each others’ interfaces are. Now in the worst case the central ESB grows a team to support it. This is, after all, the obvious things to do, every service in the organisation wants changes all the time to what they use/expose from/to each other and therefore in order to prevent everyone hacking away at the ESB and general chaos the ESB team is created. All requests for change to the ESB go to the ESB team.
The ESB team are now furiously busy and considered heros for helping everyone communicate and are the first port of call from each service team to get what they need from the rest of the organisation. Soon they are getting requests for new functionality, however they don’t know how to change the services and perhaps it’s a little tricky to work out which service should handle that functionality so they slip a little bit of business logic into the ESB and call it orchestration, after all orchestration is what ESBs are for. This continues for a number of years until it dawns on everyone that the ESB contains most, or at least significant portions of the business logic and the services have become no more than CRUD layers over databases.
Figure 2. ESB technology used a sensible way
Figure 2. is ESB technology used in a more appropriate way, of course it is no longer a true ESB, because it isn’t “Enterprise”, it isn’t just one service bus for the entire enterprise. Each service uses ESB technology within itself to ensure their interface can be stable, they can use it to maintain multiple versions of the interfaces simultaneously but that is within the service. The service team has complete autonomy over what happens with their service now. In many cases they don’t need expensive software to do this, they can simply code it in the programming language of choice or use a simple library to achieve things like mediation, routing, location, security etc. Once each service has this capability the requirement for a central ESB team falls away entirely. As the organisation has been sensible and assigned teams for each service then those team speak to each other directly to get new functionality. The act of the teams talking directly to each other, face to face, person to person about their requirements also improves overall understanding of the organisations software assets.
Below I address some of the common reasons people give for using central ESBs and suggest more appropriate patterns for achieving the desired outcome.
The ESB Protects Me From Change
The argument here is that if you want Service A to call Service B you’d better go through the ESB in case Service B’s interface changes.
What should happen is that Service B publishes an interface and guarantees it won’t change for a period of time (say 12 months), if changes are required another version of just the interface is created and the old version is mediated on to that new version.
That’s quite a bit to take on so I’ll give a simple example. A company builds a service with an operation that exposes the price of various commodities, it returns a MoneyValue response:
MoneyValue getPriceOfGold()
This works perfectly until functional requirement gets added to return the price of silver too. The architects, being smart, realise this is probably not the last metal they will be asked to add and so they create a method that’s more flexible and looks like
MoneyValue getPriceOfMetal(Metal metal)
However there are several consumers of the old getPriceOfGold method. In order to support these clients they leave the old service interface in place but redirect calls from getPriceOfGold to getPriceOfMetal(gold)within the service and everyone is happy. Eventually they will ask consumers of getPriceOfGold() upgrade to getPriceOfMetal(Metal metal).
Therefore you don’t need a central ESB to achieve this objective, you don’t need anything outside the service but a bit of mediation logic in your service.
Extra Level of Protection
Just to quickly address the oft retort to the above that a central ESB gives another layer of protection, yes it does, but it comes with all the draw backs of the central ESB: adding logic in the wrong places, functional enchancement bottleneck and so forth.
The ESB Allows Me To Orchestrate Services
Orchestration is either business logic, which belongs in the service, this is the point of services after all, they contain your logic and data, or if it is simply a case of moving a human through some process or other then that belongs in the UI code (e.g. register for a website and then add something to your basket).
The ESB Can Mediate My Data
Yes it can but see above section ‘The ESB Protects Me From Change’, the mediation can be achieve much more sensibly in your service.
The ESB Can Locate My Services
Each service should have a mechanism for locating any other service for the purposes of RPC calls. I prefer to use DNS in most cases (e.g. metal-exchange.example.com would resolve to the metal exchange service interface or API), DNS has huge power but can be used very simply too. Bonjour (aka Zeroconf) is a often cited as a solution too and it’s a good answer but it merely some extentions to DNS at the end of the day. Others suggest things like UDDI but I have never found the need myself.
The ESB Can Do My Routing
For services that subscribe to events from other service, the same process can be used for locating those topics/queues, DNS to find the broker and well named and documented topics/queues on those brokers. Most message brokers provide means of routing messages from location to location sensibly, if yours doesn’t, get another.
The ESB Can Monitor My Services
Your services should provide monitoring information over any number of technologies that can be monitored by any number of technologies. Examples of technologies that can enable your services to be monitored are syslog, JMX, SNMP, Windows Events and simple log files — one or more of these are available in just about every language. Examples of technologies that can monitor those technologies are Nagios, OpenNMS and any number of commerical systems. You don’t need an ESB to do this.
The ESB Provides Extra Security
No they don’t, they remove security by terminating it prematurely. They open you to either deliberate or mistaken man in the middle attacks.