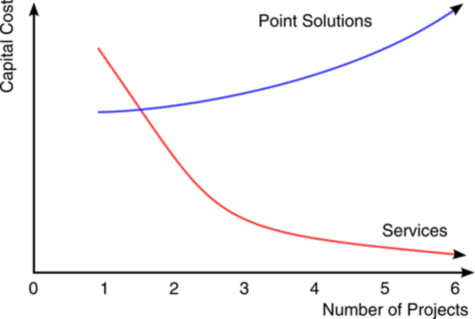
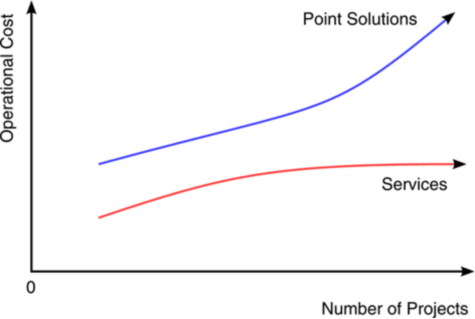
The Simplest Blog That Might Work
I’m aiming for a simple, fast and minimalist blog. A blog where writing posts is all I have to think about, not themes, fancy backgrounds, AJAX, hosting services, cloud APIs and well one starts to lose the will to live.

The design goals are:
- simple
- cheap
- fast
I’m quite pleased with the way it works, it’s probably not for technophobes but then nor is blogging. In order to publish a post you create a new text file with your post in it in a simple directory structure, if you have any images, video etc then you drop them in a “resources” folder. If you’d like some formatting in your post you can use markdown. After that, run a simple script and everything is taken care of: it’s published to the web. So far my limited posts look like this in the directory structure:
$ tree --charset US-ASCII posts/
posts/
|-- 20120216
| |-- article.yaml
| `-- resources
| |-- First-Project-Syndrome-Figure1.png
| `-- First-Project-Syndrome-Figure2.png
`-- 20131230
`-- article.yaml
3 directories, 4 files
How it works
The markdown from the YAML file is converted to HTML, which is minified (optimised to remove redundant spaces etc), and then put into a folder which btsync is watching, once a change is noticed it is synced to all computers with btsync installed on, including, most importantly the web server.
A Note On DNS
As I’m hosting this on my home broadband connection, which doesn’t have a static IP address, I needed a way to update my DNS record quickly every time my IP address changed. To do this I used a free service DNSdynamic which gives you a subdomain on one of their domains (e.g. example.dnsdynamic.com), I chose andyhedges.http01.com but anything would work, you then install a client which regularly checks your IP address and updates the DNS if need be. This is great but I wanted to use my vanity domain name hedges.net, I therefore configured a CNAME with my DNS registrar to point blog.hedges.net to andyhedges.http01.com and I was in business, DNS-wise at least.
Costs
The cost of my blogging platform breaks down as below:
- software - £0 (all open source or freeware)
- hosting - £0 (using my home fibre connection)
- hardware
- Raspberry Pi - £28.99
- Power Supply - £0 (free with phone)
- Network Cable - ~£1
- SD Card - ~£4
- DNS - £0 (using my DNS registrar and Dynamic DNS provider)
There we have it, a blogging platform for thirty four quid that doesn’t require 3rd party hosting. It remains to be seen if my ISP gets cross.
Benchmarks
On the little R’berry Pi a quick benchmark with no optimisation shows it can handle 250 requests per second with a response time of 3ms (across my home gigabit network).
Todo
There are still a few more to-dos:
- preview mode
- comments (I think I’ll use disqus or maybe G+)
- RSS
- optimising Nginx (e.g. gzip or sdch, SPDY, threads and so forth)
- smartypants-like substitution
- Open Source it (tidy code, add licenses put it on github)
- Set up a 301 Moved Permanently on a virtual host for the Dynamic DNS name
Full details
For those interested the full details of software, hardware and network.
The tools I’ve chosen for the client side are are:
- Notepad (although sublime, textpad, gedit or vi would do), this is for editing the posts
- btsync this enables me to keep the webservers and any computer I use in sync with all of the generate content, the source information and templates, more on that later
The development tools:
- OpenJDK 8 I wanted to use Lambdas…
- IntelliJ IDEA Community Edition to develop the Java code
The software libraries:
- SnakeYaml this is a YAML binding for Java, YAML is basically a human friendly information format, similar to XML or JSON but unlike those two easy to read and write for us humans.
- FreeMarker is a templating language similar to JSP or Razor and provides an easy library to integrate it with your projects
- Actuarius a markdown to HTML converter
- htmlcompressor an HTML minification library
- YUI Compressor a CSS minification library
The server side software:
- Nginx a nice, light, fast HTTP server
- btsync see above
- ddclient The Dynamic DNS client that allows me to have my DNS record updating when my ISP changes my IP address
- Raspbian A Debian Linux variant for the Raspberry Pi
The hardware:
- Raspberry Pi a circuit board sized computer
- Indian takeaway container, no this isn’t the wacky name of some kickstarter project, I used one of the plastic tubs that takeaway curry comes in to provide a case for the Raspberry Pi, it keeps dust and/or water off it
- Mini USB charger plug and cable from my Nexus 5 (I have so many of these and so I chose a smallish one)
- Network cable from my man draw
The network:
- Existing Fibre connection and associated routers and access points
- Netgear Gigabit Switch